Building a Scalable PostgreSQL Solution
Table of Contents
PostgreSQL provides several ways to implement replication that would maintain a copy of the data from a database on another server or servers. This can be used in many scaling scenarios. Its primary purpose is to create and maintain a backup database in case of system failure. This is especially true for physical replication. However, replication can also be used to improve the performance of a solution based on PostgreSQL. Sometimes, third-party tools can be used to implement complex scaling scenarios.
This article is taken from the book Learning PostgreSQL 11 - Third Edition by Salahaldin Juba and Andrey Volkov. This book will familiarize you with the latest features in PostgreSQL 11, and get you up and running with building efficient PostgreSQL database solutions from scratch.
In this article, we will learn how to handle multiple heavy queries at the same time using PostgreSQL features as well as third-party solutions. We will also look at the concept of data sharding and different sharding tools.
1. Scaling for heavy querying
Imagine there's a system that's supposed to handle a lot of read requests. For example, there could be an application that implements an HTTP API endpoint that supports the auto-completion functionality on a website. Each time a user enters a character in a web form, the system searches in the database for objects whose name starts with the string the user has entered. The number of queries can be very big because of the large number of users, and also because several requests are processed for every user session. To handle large numbers of requests, the database should be able to utilize multiple CPU cores. In case the number of simultaneous requests is really large, the number of cores required to process them can be greater than a single machine could have.
The same applies to a system that is supposed to handle multiple heavy queries at the same time. You don't need a lot of queries, but when the queries themselves are big, using as many CPUs as possible would offer a performance benefit—especially when parallel query execution is used.
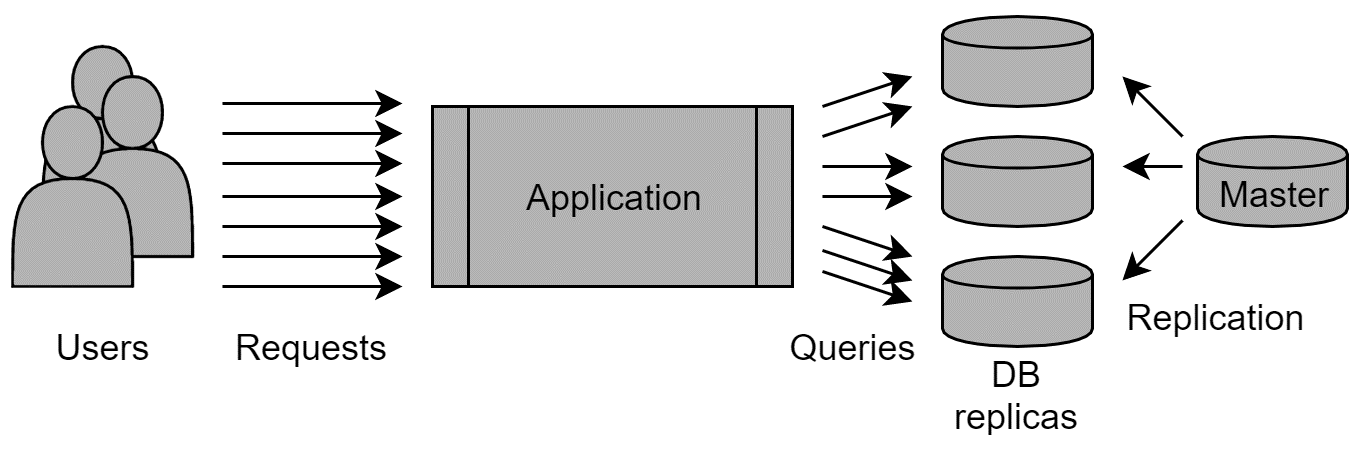
In such scenarios, where one database cannot handle the load, it's possible to set up multiple databases, set up replication from one master database to all of them, making each of them work as a hot standby, and then let the application query different databases for different requests. The application itself can be smart and query a different database each time, but that would require a special implementation of the data-access component of the application, which could look as follows:
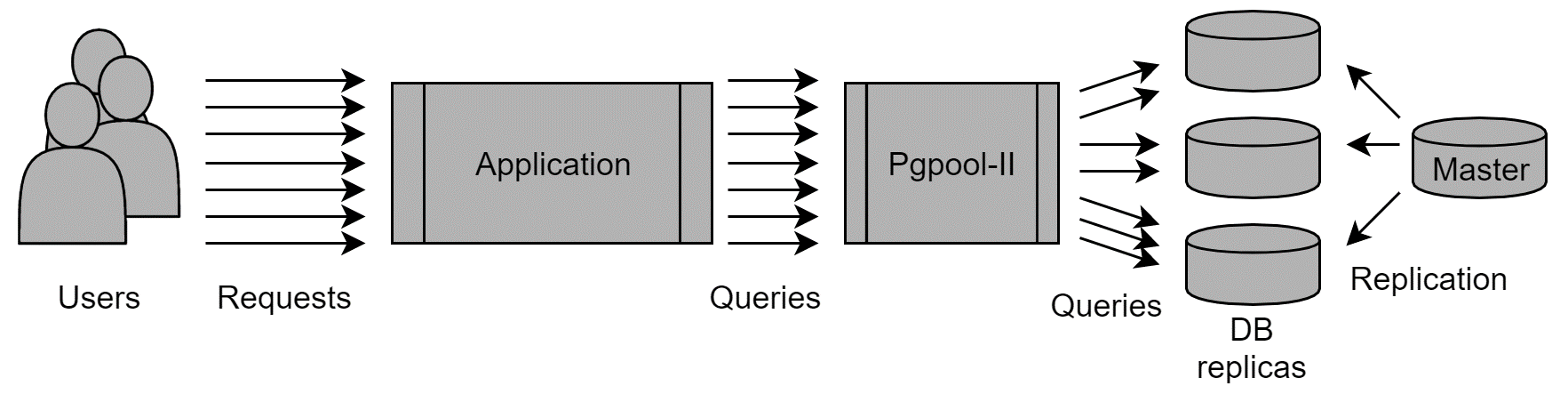
Another option is to use a tool called Pgpool-II, which can work as a load-balancer in front of several PostgreSQL databases. The tool exposes a SQL interface, and applications can connect there as if it were a real PostgreSQL server. Then Pgpool-II will redirect the queries to the databases that are executing the fewest queries at that moment; in other words, it will perform load-balancing:
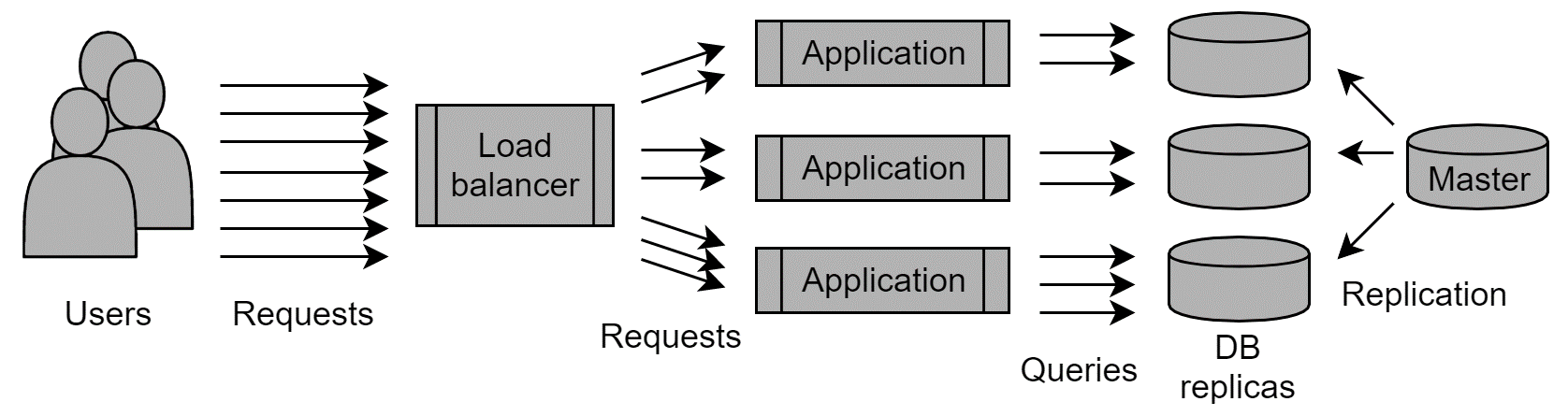
Yet another option is to scale the application together with the databases so that one instance of the application will connect to one instance of the database. In that case, the users of the application should connect to one of the many instances. This can be achieved with HTTP load-balancing:
2. Data sharding
When the problem is not the number of concurrent queries, but the size of the database and the speed of a single query, a different approach can be implemented. The data can be separated into several servers, which will be queried in parallel, and then the result of the queries will be consolidated outside of those databases. This is called data sharding.
PostgreSQL provides a way to implement sharding based on table
partitioning, where partitions are located on different servers and
another one, the master server, uses them as foreign tables. When
performing a query on a parent table defined on the master server,
depending on the WHERE clause and the definitions of the
partitions, PostgreSQL can recognize which partitions contain the
data that is requested and would query only these
partitions. Depending on the query sometimes joins, grouping, and
aggregation could be performed on the remote servers. PostgreSQL can
query different partitions in parallel, which will effectively
utilize the resources of several machines. Having all this, it's
possible to build a solution when applications would connect to a
single database that would physically execute their queries on
different database servers depending on the data that is being
queried.
It's also possible to build sharding algorithms into the applications that use PostgreSQL. In short, applications would be expected to know what data is located in which database, write it only there, and read it only from there. This would add a lot of complexity to the applications.
Another option is to use one of the PostgreSQL-based sharding solutions available in the market or open source solutions. They have their own pros and cons, but the common problem is that they are based on previous releases of PostgreSQL and don't use the most recent features (sometimes providing their own features instead).
One of the most popular sharding solutions is Postgres-XL, which implements a shared-nothing architecture using multiple servers running PostgreSQL. The system has several components:
- Multiple data nodes: Store the data
- A single global transaction monitor (GTM): Manages the cluster, provides global transaction consistency
- Multiple coordinator nodes: Supports user connections, builds query-execution plans, and interacts with the GTM and the data nodes
Postgres-XL implements the same API as PostgreSQL, therefore the
applications don't need to treat the server in any special way. It
is ACID-compliant, meaning it supports transactions and integrity
constraints. The COPY command is also supported.
The main benefits of using Postgres-XL are as follows:
- It can scale to support more reading operations by adding more data nodes
- It can scale for to support more writing operations by adding more coordinator nodes
- The current release of Postgres-XL (at the time of writing) is based on PostgreSQL 10, which is relatively new
The main downside of Postgres-XL is that it does not provide any high-availability features out of the box. When more servers are added to a cluster, the failure probability of any of them increases. That's why you should take care with backups or implement replication of the data nodes themselves.
Postgres-XL is open source, but commercial support is available.
Another solution worth mentioning is Greenplum. It's positioned as an implementation of a massive parallel-processing database, specifically designed for data warehouses. It has the following components:
- Master node: Manages user connections, builds query execution plans, manages transactions
- Data nodes: Store the data and perform queries
Greenplum also implements the PostgreSQL API, and applications can
connect to a Greenplum database without any changes. It supports
transactions, but support for integrity constraints is limited. The
COPY command is supported.
The main benefits of Greenplum are as follows:
- It can scale to support more reading operations by adding more data nodes.
- It supports column-oriented table organization, which can be useful for data-warehousing solutions.
- Data compression is supported.
- High-availability features are supported out of the box. It's possible (and recommended) to add a secondary master that would take over in case a primary master crashes. It's also possible to add mirrors to the data nodes to prevent data loss.
The drawbacks are as follows:
- It doesn't scale to support more writing operations. Everything goes through the single master node and adding more data nodes does not make writing faster. However, it's possible to import data from files directly on the data nodes.
- It uses PostgreSQL 8.4 in its core. Greenplum has a lot of improvements and new features added to the base PostgreSQL code, but it's still based on a very old release; however, the system is being actively developed.
- Greenplum doesn't support foreign keys, and support for unique constraints is limited.
There are commercial and open source editions of Greenplum.
3. Scaling for many numbers of connections
Yet another use case related to scalability is when the number of database connections is great. When a single database is used in an environment with a lot of microservices and each has its own connection pool, even if they don't perform too many queries, it's possible that hundreds or even thousands of connections are opened in the database. Each connection consumes server resources and just the requirement to handle a great number of connections can already be a problem, without even performing any queries.
If applications don't use connection pooling and open connections only when they need to query the database, and close them afterwards, another problem could occur. Establishing a database connection takes time—not too much, but when the number of operations is great, the total overhead will be significant.
There is a tool, named PgBouncer, that implements a connection-pool functionality. It can accept connections from many applications as if it were a PostgreSQL server and then open a limited number of connections towards the database. It would reuse the same database connections for multiple applications' connections. The process of establishing a connection from an application to PgBouncer is much faster than connecting to a real database, because PgBouncer doesn't need to initialize a database backend process for the session.
PgBouncer can create multiple connection pools that work in one of the three modes:
- Session mode: A connection to a PostgreSQL server is used for the lifetime of a client connection to PgBouncer. Such a setup could be used to speed up the connection process on the application side. This is the default mode.
- Transaction mode: A connection to PostgreSQL is used for a single transaction that a client performs. That could be used to reduce the number of connections at the PostgreSQL side when only a few translations are performed simultaneously.
- Statement mode: A database connection is used for a single statement. Then it is returned to the pool and a different connection is used for a next statement. This mode is similar to the transaction mode, though more aggressive. Note that multi-statement transactions are not possible when statement mode is used.
Different pools can be set up to work in different modes.
It's possible to let PgBouncer connect to multiple PostgreSQL servers, thus working as a reverse proxy. The way PgBouncer could be used is represented in the following diagram:

PgBouncer establishes several connections to the database. When an application connects to PgBouncer and starts a transaction, PgBouncer assigns an existing database connection to that application, forwards all SQL commands to the database, and delivers the results back. When the transaction is finished, PgBouncer will dissociate the connections, but not close them. If another application starts a transaction, the same database connection could be used. Such a setup requires configuring PgBouncer to work in transaction mode.
4. Further Reading
This article walked you through the different scalability use cases and how to handle them in PostgreSQL. If you found this post useful, do check out the book, Learning PostgreSQL 11 - Third Edition by Packt Publishing. This book will give you a thorough understanding of PostgreSQL 11 and help you develop the necessary skills to build efficient database solutions.